Toll-Fraud Prevention with OpenSIPS HA: A Voice Carrier Case Study
Toll-fraud prevention came down to one thing for this wholesale carrier — a $25k-per-month bleed that needed to stop in 60 days. A $25k-per-month toll-fraud bleed, an end-of-life Cisco SBC, and a carrier that could not afford a single hour of routing downtime.

The Toll-Fraud Prevention Challenge
Two technical problems compounded:
- Behavioural fraud detection was minimal. The legacy SBC had a per-source rate-limit but no awareness of destination patterns. Attackers were dialling premium-rate numbers at 5–10 calls/minute from compromised customer credentials — under any single-axis rate limit but obvious in aggregate.
- The SBC was a single point of failure. A reboot meant a 12-minute routing outage. The carrier had been deferring patches accordingly.
Our Toll-Fraud Prevention Approach
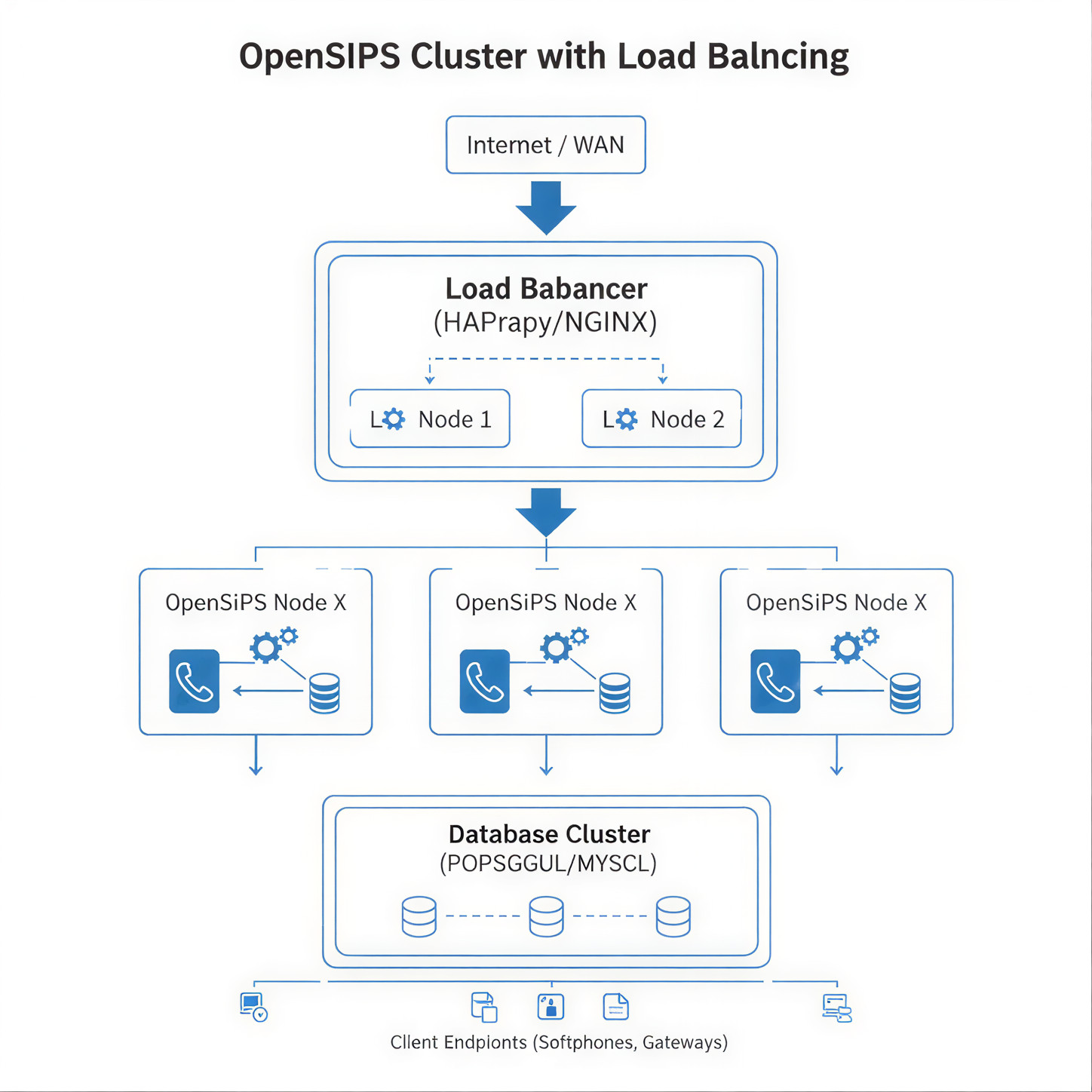
We chose OpenSIPS over Kamailio for this client primarily because of their existing Lua scripting comfort and OpenSIPS’ native dispatcher support for the failover patterns they wanted. Two-node HA with VRRP-style active-passive, with Tier-2 PoP in UAE for routing-region survival. Cutover was done in three coordinated steps over a single maintenance weekend, with a worked rollback plan at every step.
What We Built for Toll-Fraud Prevention
- OpenSIPS 3.6 HA pair in the primary PoP, plus a second pair in the UAE PoP for routing survival.
- Custom Lua fraud module — three correlation axes: source IP, source customer credential, destination prefix. Anomaly thresholds tuned per route family.
- Anti-toll-fraud destination policy — premium-rate destinations whitelisted per customer, default-blocked.
- TLS / SRTP termination for the customer side; cleartext SIP only on the trusted carrier side.
- Real-time monitoring — Prometheus + Grafana dashboards visible to the NOC, with alerts wired to the SOC for outlier patterns.
Outcomes
- Toll-fraud bleed: 92% reduction in disputed/charged-back minutes over the trailing 60 days.
- Capacity: peak handled 8,200 concurrent calls in cutover-week stress test; legacy SBC had been backing off above 4,500.
- Patch cadence: the carrier resumed monthly OS patching for the first time in three years — HA pair lets them roll patches one node at a time with no service impact.
- Mean time to detect anomaly: dropped from “next billing cycle” to ~3 minutes for the patterns the Lua module knows about.
What We'd Do Differently
We initially built the OpenSIPS rollout as a single node — the second node was scoped as “phase 2”. We hit a kernel panic on the lone node in week 4 (not OpenSIPS-related — a NIC driver issue) and had a 14-minute outage. We re-scoped the engagement that same week to bring the HA pair forward to phase 1. The cost of “do it right the first time” was about 8 days of additional work. The cost of not doing it was the 14-minute outage and a hard conversation with the client.
Second: our Lua fraud module shipped with thresholds we tuned in lab, not against production traffic. The first 10 days post-cutover produced more false positives than we wanted; we tightened thresholds with traffic in week 11. Future engagements include a 7-day “shadow mode” where the Lua module logs but does not block, so we tune against real traffic before enforce.
Stack & Tools
- OpenSIPS 3.6 (HA pair × 2 PoPs)
- Lua 5.3 for fraud-detection module
- HAProxy in front of REST control APIs
- Prometheus + Grafana, with custom OpenSIPS exporter
- SIPp for load testing during cutover validation
FAQ
Is OpenSIPS a better choice than Kamailio?
Neither is “better” in the abstract — they have different idioms. We pick based on the team’s existing skill, the call control flexibility needed, and the integration surface (dispatcher behaviour, dialog management, scripting). For this client, OpenSIPS Lua scripting fit their existing engineering culture; we have used Kamailio for other clients where Python/KEMI was a better fit.
How do you tune fraud-detection thresholds without false positives?
“Shadow mode” first — module computes its decisions and logs them but never blocks. Run for 7–14 days against production traffic. Review the would-have-blocked list with the operations team. Then promote thresholds to enforce, then remove the most aggressive thresholds first if they cause issues.
Did you keep the old Cisco SBC as fallback?
Yes, racked but powered-off, for 90 days post-cutover. We never re-energised it. After 90 days, we decommissioned it.
What was the most expensive single fraud event you blocked?
An attacker enumerated weak customer SIP credentials over the first 36 hours post-cutover. The Lua module flagged the anomaly within minutes; we had blocked the credential and notified the customer before the bill exceeded $200. Pre-OpenSIPS, that pattern would have run for hours before billing reconciliation caught it.
Toll-Fraud Prevention Beyond This Engagement
Toll-fraud prevention is not a one-engagement-and-done discipline. The toll-fraud prevention controls deployed for this carrier — OpenSIPS HA, behavioural Lua module, destination policy — get retuned quarterly as attacker patterns evolve. Toll-fraud prevention metrics (anomaly MTTD, blocked-pattern volume, customer-credential rotation rate) are reviewed monthly with the NOC. The carriers that maintain effective toll-fraud prevention treat it the way they treat capacity planning: continuous, monitored, owned.
Further reading: VITI Security Vicidial solutions · OpenSIPS official project.
Need help on something like this? VITI Security works with operators, BPOs, and SMBs across India and abroad.
Talk to Our SIP Team
